- Date: January 14, 2024
- Categories: Deep LearningNatural Language ProcessingPython
Live Demo
Experience TasteMatch, the restaurant recommender in action! View the Web App to see how my innovative solution transforms the way you discover and enjoy new restaurants.
Project Overview
Choosing a new restaurant can often feel like a roll of the dice, leading many of us to stick with familiar options rather than risk an unsatisfactory experience. This hesitancy masks the thrill of culinary discovery. The central challenge I wanted to address with my project, TasteMatch, was this very uncertainty and limited exposure to restaurant selection. The vision was clear: to create a system that precisely matches individual dining preferences with potential restaurant options by analyzing a wealth of user reviews and experiences.
Motivation Behind the Project
Like many others, I found myself repeatedly gravitating towards familiar dining spots, hesitant to try new restaurants due to the fear of disappointment. This reluctance not only limited my culinary experiences but also highlighted a gap in existing restaurant recommendation systems. Most models relied heavily on user ratings, proximity, or cuisine types, lacking a nuanced understanding of individual preferences across different locations.
Unsatisfied with the generic nature of existing solutions, I embarked on a journey to create something more personalized. The goal was to develop a model that recommends restaurants based not just on general preferences but tailored to the unique tastes of individuals in any major city in the United States. This led to the inception of TasteMatch – a web app designed to break the cycle of dining repetition and open up a world of new flavours and experiences.
Preparing the Data
Finding the right data was a challenge. Existing sources like Kaggle didn’t offer what I needed, compelling me to create a unique dataset, especially for this project. I tapped into the Yelp API to gather information on over 80,000+ restaurants across major U.S. cities.
However, due to limitations on the Free API, I had access to only 3 reviews per restaurant. Since constructing a restaurant recommendation system based on reviews demanded more data, particularly in the review domain, I explored alternative solutions.
As a result, I wrote a web scraping script using Python packages such as BeautifulSoup. This custom dataset played a crucial role in the project’s ultimate success.
A Personal Learning Curve
The task of scraping data for over 80,000 restaurants individually using a for loop seemed impractical, with an initial calculation estimating it would take 64 hours. Faced with this challenge, I began exploring alternative approaches. It was during this phase that I delved into the concept of concurrent execution through threading, workers, and proxy rotation. This exploration was not just about finding a faster way to scrape data; it was an educational journey in advanced programming concepts.
Understanding the Methodology
TasteMatch distinguishes itself from conventional restaurant-finding apps by utilizing advanced Natural Language Processing (NLP) and Word2Vec algorithms, along with content-based filtering techniques. Content-based filtering is a method of recommendation that uses item features to recommend additional items similar to what the user likes, based on their previous actions or explicit feedback. In the context of TasteMatch, this method analyzes the content of restaurant reviews to identify and understand the intricacies of dining experiences. By examining patterns within the reviews, the app can suggest new restaurants that closely align with a user’s preferences. This personalized approach ensures that each recommendation is tailored to the user, mirroring their unique dining history and expressed culinary interests.
For those intrigued by the technicalities of NLP and Word2Vec, I invite you to explore my blog. There, you will find an in-depth article where I explain the Word2Vec algorithms, providing insights into how they empower the TasteMatch app.
NLP and Word2Vec at the Core
In developing TasteMatch, I delved deep into the realm of Natural Language Processing (NLP) to unravel the complex semantic content of restaurant reviews. The choice of the Word2Vec skip-gram model was pivotal. Unlike conventional models(TD-IDF, CBOW), the skip-gram architecture excels in handling unique culinary terminologies and nuanced expressions found in user reviews. This approach allowed for a more refined analysis, capturing subtle preferences and sentiments that standard models might overlook.
Capturing Similarity
The essence of TasteMatch lies in its ability to generate tailored restaurant recommendations. By computing similarity scores between the word embeddings of various restaurants, the app suggests options that resonate closely with users’ tastes. This feature transformed TasteMatch from a simple search tool into a personalized culinary guide, offering users a chance to explore new dining horizons that align with their preferences.
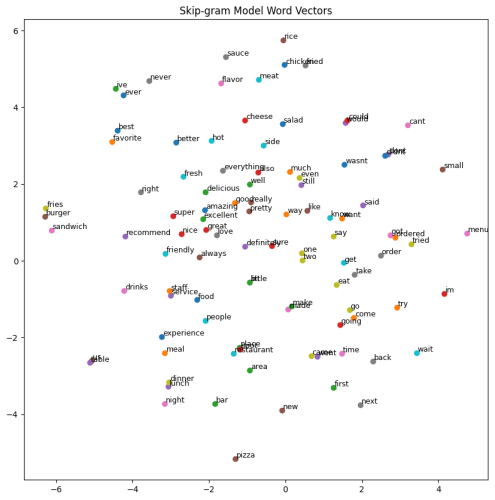
From the observed scatter plot, it is evident that words such as “restaurant” and “place” are closely aligned, and similarly, positive descriptors like “amazing,” “excellent,” “great,” “delicious,” “good,” and “pretty” are grouped, showcasing their comparable values in the vector space. This clustering indicates that when a review includes phrases like “This place is great” and “This restaurant is amazing,” the model will recognize a high degree of similarity between them.
This effectiveness in identifying semantic relationships between words, even when they are different but used in similar contexts, underscores the strength of the skip-gram model in our NLP application. It demonstrates the model’s ability to go beyond mere word matching, capturing the essence of context and meaning in language, which is crucial for accurate sentiment analysis in customer reviews.
Deploying and Learning with Streamlit and Docker
Deploying the app was a journey in itself. Streamlit was chosen for its simplicity and effectiveness in turning data scripts into shareable web apps. It provided the perfect platform to bring TasteMatch to life, showcasing the NLP model’s capabilities in a user-friendly format.
A Personal Learning Curve
This project was also a personal journey in skill enhancement. I was keen to learn Docker and integrate it for streamlined deployment. The project was an amalgamation of solving a real-world problem, implementing complex AI techniques, and self-development.
Conclusion
The project “TasteMatch” was embarked upon to address a common dilemma: the uncertainty and hesitancy in choosing new restaurants. This often leads to a fallback to familiar choices, overshadowing the excitement of discovering new culinary delights. The core challenge was to mitigate this fear of unsatisfactory dining experiences and limited exposure to diverse culinary options. By implementing the skip-gram model in our NLP framework, we have successfully developed a system that accurately understands and matches individual dining preferences with potential restaurant options. This was achieved by conducting a comprehensive analysis of existing user reviews and experiences. As a result, TasteMatch has paved the way for a more confident and personalized approach to exploring new dining experiences, turning what once was a gamble into an exciting adventure of culinary discovery.
References
- Yelp Developer Portal: Provided necessary documentation for Yelp API and acted as a key resource for accessing restaurant information.
- Test Similarity with Word Embeddings: Insightful literature on the application and efficacy of Word2Vec models in evaluating semantic similarity.
- Streamlit documentation: Comprehensive guide and reference for developing and deploying the web application using Streamlit.
- Scraping Yelp Data in Python: A comprehensive guide which acted as a key resource in scraping Yelp restaurant review data.
- Introduction to Docker (YouTube): An informative video resource offering a beginner-friendly introduction to Docker and its functionalities.
- Python Documentation on Concurrent Execution: Official Python documentation detailing the methods and best practices for implementing concurrent execution, including threading and multiprocessing.