Hello all, I trust your year has kicked off brilliantly! Before we dive into our first knowledge-rich article, let’s appreciate the significance of natural language processing (NLP). NLP is pivotal in how we interact with technology, revolutionizing communication between humans and machines. It’s the backbone of various applications, from voice assistants to language translation, making it a cornerstone in today’s digital world. With this context in mind, I’m excited to introduce a foundational element of NLP – ‘Term Frequency – Inverse Document Frequency‘, commonly referred to as TF-IDF. I stumbled upon this intriguing concept while working on a project recently, and it struck me as something worth sharing. So, let’s embark on this learning journey together!
Understanding the concept
TF-IDF is a popular technique in natural language processing and information retrieval, evaluating the significance of a term in a document compared to a set of documents, or a corpus. Let’s break it down!
TF(Term Frequency)
The term TF stands for “Term Frequency” and means the frequency of a particular term you are concerned with relative to the document.
For example, let’s consider two short restaurant reviews to illustrate how term frequency (TF) is calculated.
Review A – The Pasta in this restaurant is good. Review B – The Noodles in this restaurant is tasty.
Each review is treated as a separate document in our corpus. We’ll assume that each review consists of exactly 7 words to keep the calculations simple. Here’s how we can calculate the TF for each unique word in the reviews:

IDF(Inverse Document Frequency)
The term IDF stands for Inverse Document Frequency and is calculated by

Image Source: https://towardsdatascience.com/understanding-term-based-retrieval-methods-in-information-retrieval-2be5eb3dde9f
Here’s what each component means:
- idf(t): The inverse document frequency of term t.
- log: This is the logarithm. Using the logarithm reduces the impact of the ratio when the document frequency is high, preventing it from pulling the IDF too low.
- N: The total number of documents in the collection. This is the size of your dataset or corpus.
- df(t): The document frequency of term t. This is the number of documents in which the term t appears.
In simple words, the IDF measures the importance of the term t in the entire collection of documents. If a term appears in many documents, its document frequency (df(t) is high, and the ratio N/df(t) becomes smaller. When you take the logarithm of a smaller ratio, the result is a lower IDF score, which indicates the term is less important because it’s common.
Conversely, if a term appears in fewer documents, the ratio N/df(t) is larger, and the logarithm of this larger ratio results in a higher IDF score. A higher IDF score suggests the term is more significant in the collection because it is rare.
Now applying this to our example, we get the following.

TD – IDF(Term Frequency – Inverse Document Frequency)
Now putting the pieces together, TD-IDF is given by multiplying the both term frequency and Inverse Document frequency as shown in the formula below.
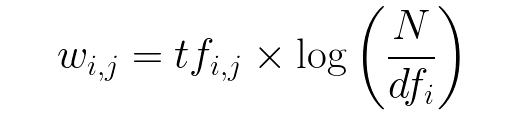
Image Courtesy: https://www.freecodecamp.org/news/how-to-process-textual-data-using-tf-idf-in-python-cd2bbc0a94a3/
By applying the formula in our example, it would result in the following table
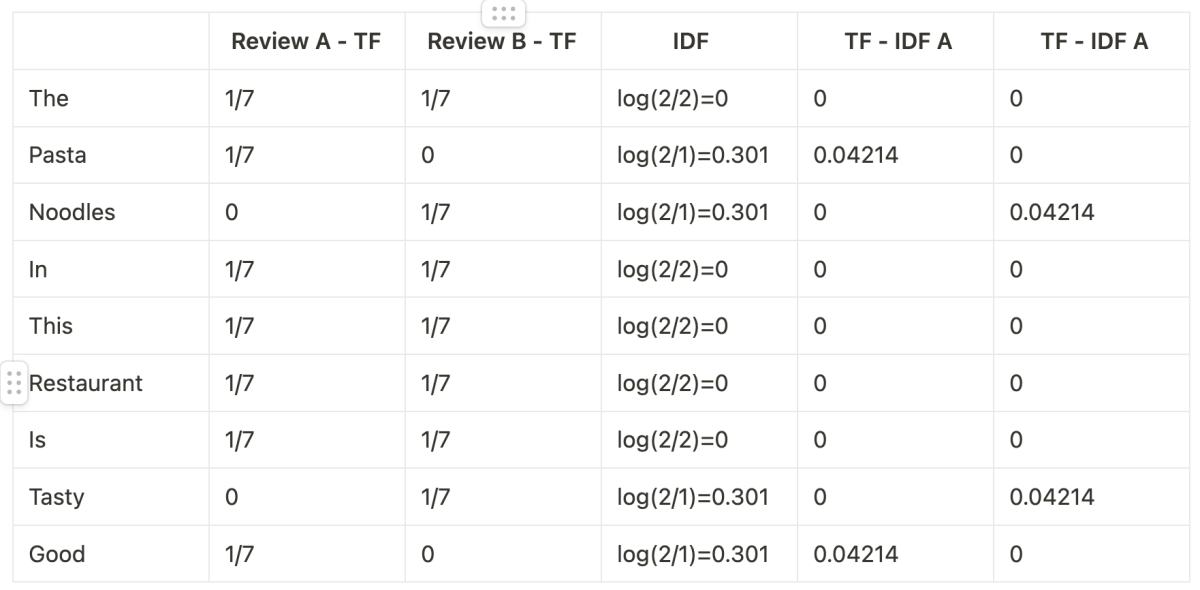
So from this, we can interpret that in Review A, the most important words are ‘Pasta‘ and ‘Good‘, while in Review B the most important words are ‘Noodles‘ and ‘Tasty‘.
Implementation in python
Now that we’ve understood the math behind TF-IDF, let us learn how to implement it in Python which is the easiest part of this article!
from sklearn.feature_extraction.text import TfidfVectorizer
# Define the reviews
review_a = "The Pasta in this restaurant is good."
review_b = "The Noodles in this restaurant is tasty."
# Combine the reviews into a list
corpus = [review_a, review_b]
# Create a TF-IDF vectorizer
vectorizer = TfidfVectorizer()
# Fit and transform the corpus
tfidf_matrix = vectorizer.fit_transform(corpus)
# Get the feature names (words) from the vectorizer
feature_names = vectorizer.get_feature_names_out()
# Create a DataFrame for better readability (optional)
import pandas as pd
df = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names, index=['Review A', 'Review B'])
# Print the TF-IDF values
print("TF-IDF Values:")
print(df)and the output to the above code would look like this

Please note that in practical scenarios, the Inverse Document Frequency (IDF) will rarely be zero because it’s uncommon for a word to appear in every document exactly the same number of times as there are documents in the corpus. Furthermore, to manage situations where a word might not appear at all, the scikit-learn library adds 1 to the denominator in the IDF formula. Additionally, scikit-learn employs the natural logarithm (ln) instead of the base-10 logarithm (log). This adjustment accounts for the difference between our manual calculations and the output you might see from scikit-learn. However, the underlying principle remains consistent.
When to use TF-IDF?
When you’re sifting through a mountain of text, looking to surface what matters most, TF-IDF is your go-to tool. It’s particularly handy in search engines to elevate the most relevant documents to the top of your search results. Imagine you’re digging for gold in a river of words; TF-IDF helps to sift out the key insights.
Below are a few examples of use cases where TF-IDF is typically applied
- Information Retrieval: When building search engines, TF-IDF can help rank documents based on query relevance. It enhances the accuracy of the search results by giving more weight to the most telling words in each document.
- Text Mining: TF-IDF is useful in text mining for extracting important information from large sets of textual data. It can help identify key phrases and terms that characterize a document.
- Document Clustering: When clustering documents, TF-IDF can help identify documents that are similar to each other and group them together based on the significance of shared terms.
- Keyword Extraction: TF-IDF can be used to extract keywords from documents, which can then be used for summarization or as metadata for the document.
- Dimensionality Reduction: In natural language processing, reducing the dimensionality of text data is often necessary, and TF-IDF can help by representing documents using the most important terms only.
- Content Recommendation: Recommender systems can use TF-IDF to suggest articles, papers, or other documents to users based on the similarity of content.
Pros and Cons
Like any other concept, TF-IDF has its own set of pros and cons. Let’s delve into the advantages and disadvantages of TF-IDF and illustrate one drawback using the reviews example we used earlier in the article to explain the concept.
Pros of TF-IDF:
- Weighting Term Importance: TF-IDF assigns higher weights to terms that are important in a document but not common across the entire corpus.
- Simple Implementation: As demonstrated in the implementation section, its application is relatively straightforward.
- Versatility: TF-IDF can be widely used in various natural language processing tasks such as text classification, clustering, and information retrieval.
Cons of TF-IDF:
- Lack of Semantic Understanding: TF-IDF treats terms independently and does not capture semantic relationships between words. For example, in the sentence “The Pasta in this restaurant is good.” and “The Noodles in this restaurant are tasty.” TF-IDF may not effectively capture the similarity between “pasta” and “noodles” as both are related to the concept of delicious food.
- Sensitivity to Document Length: TF-IDF can be sensitive to the length of the documents. Longer documents may have higher TF-IDF values for terms simply because they have more words, which may not necessarily indicate term importance.
Conclusion
And that’s a wrap, guys! TF-IDF is a super important concept that’s like a secret decoder ring for all the text out there. Whether you’re building the next great search engine or just trying to organize a heap of documents, it’s a pretty cool tool to have in your kit. I really hope you’ve picked up something useful from this article.
A huge shout-out to everyone who’s made it this far. Keep an eye out for our next piece, where we’ll be diving into some new methods that pick up where TF-IDF leaves off, tackling its limitations and giving us even more ways to work with words. Catch you in the next article!